Dify部署及使用
一、简介
Dify 是一个专注于 AI 应用开发的平台,提供从构思、开发到部署和监控的完整基础设施。它帮助团队构建能够投产并创造真正价值的 AI 解决方案。Dify 还提供智能化流程自动化与数据管理技术,旨在优化企业业务流程,提高工作效率。此外,Dify 是开源的,由专业团队和社区共同打造,适合多行业场景的 AI 解决方案。
二、前期须知
这里使用本地部署的dify,好处如下
大模型个人练习观摩,建议使用阿里百炼里面的大模型,里面有1000万的免费使用额度,如果个人GPU很强悍,也可以使用本地部署,企业应用建议使用本地部署,保证信息安全。

需要掌握基本的docker、pg数据库、liunx的使用
三、演示环境说明
我dify部署在ubuntu 22.04下(部署完成:docker,docker-compose),部署教程自行寻找安装
大模型应用是阿里百炼里面的大模型(deepseek-v3)
Docker管理工具:Dpanel,部署教程
ssh工具:使用的是xshell,可以使用其他连接工具
pg数据库连接工具:使用的是navicat
四、部署
4.1下载dify文件,可以通过git或者直接下载zip压缩包
GitHub - langgenius/dify: Production-ready platform for agentic workflow development.
 dify: Dify镜像仓库,原仓库地址:https://github.com/langgenius/dify,感谢dify团队以及社区的所有成员
dify: Dify镜像仓库,原仓库地址:https://github.com/langgenius/dify,感谢dify团队以及社区的所有成员
4.2修改配置文件
# 解压
xxxxxt@xxxx-PowerEdge-R710:~/xx$ unzip dify-main_2.zip
# 修改名称
xxxxxt@xxxx-PowerEdge-R710:~/xx$ mv dify-main_3/ ../dify
# 进入目录
xxxxxt@xxxx-PowerEdge-R710:~/xx$ cd dify/docker/
# 拷贝文件
xxxxxt@xxxx-PowerEdge-R710:~/xx/dify/docke$ cp .env.example .env
# 修改.env文件
## EXPOSE_NGINX_PORT=80
## EXPOSE_NGINX_SSL_PORT=443
## 改成
## EXPOSE_NGINX_PORT=8089
## EXPOSE_NGINX_SSL_PORT=4433
xxxxxt@xxxx-PowerEdge-R710:~/xx/dify/docke$ vim .env
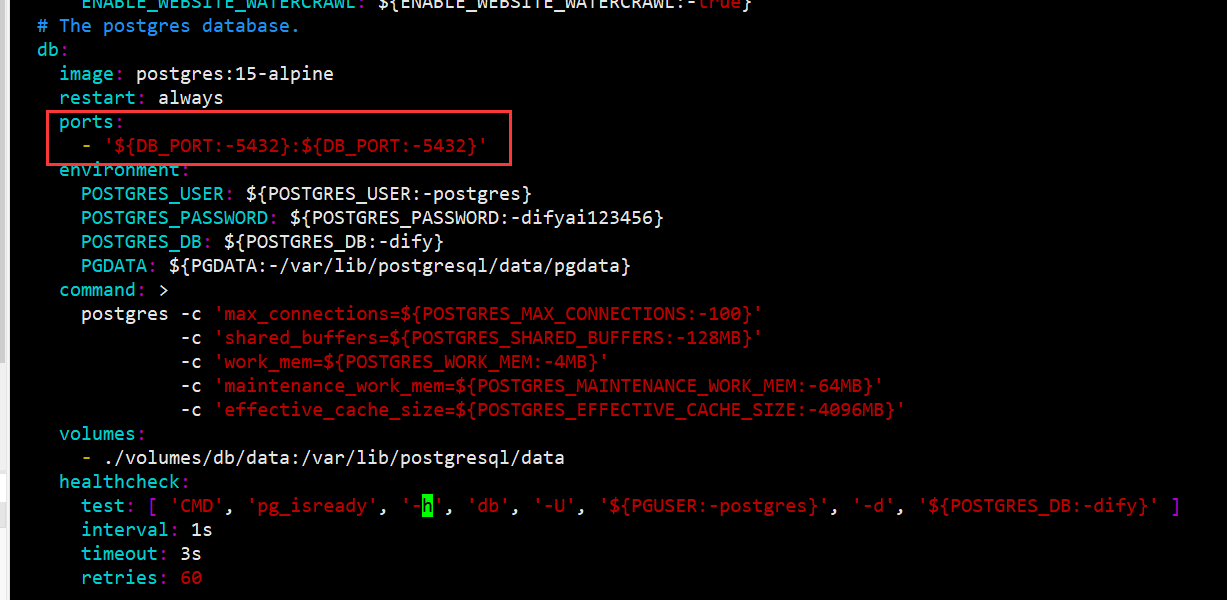
# 修改yaml文件
## postgres:15-alpine添加端口映射
## ports:
## - '${DB_PORT:-5432}:${DB_PORT:-5432}'
xxxxxt@xxxx-PowerEdge-R710:~/xx/dify/docke$ vim docker-compose.yaml
# 运行docker-compose
xxxxxt@xxxx-PowerEdge-R710:~/xx/dify/docke$ sudo docker-compose up -d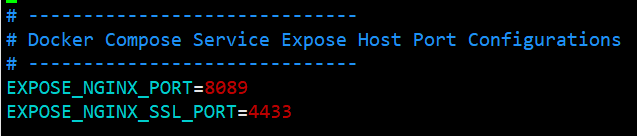

4.3进入dpanel查看容器是否正常运行
4.4使用浏览器访问:ip:8089
注:首次登陆需要设置管理员用户和密码(管理员邮箱可以随便按邮箱格式输入,如:[email protected])
五、使用
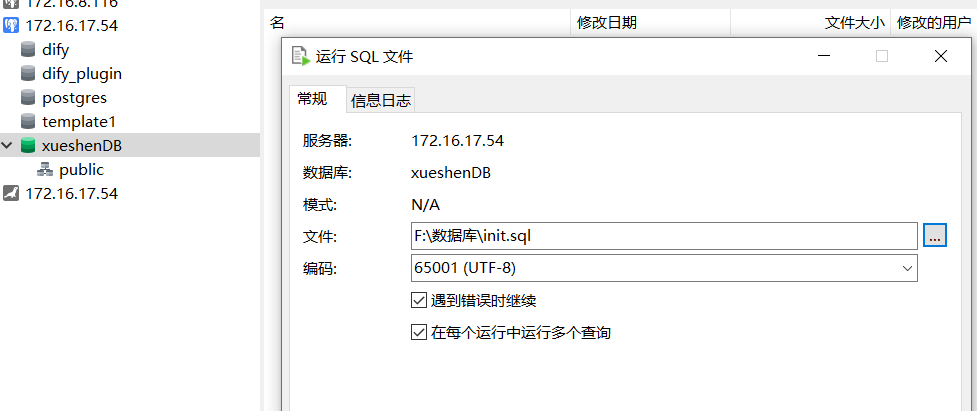
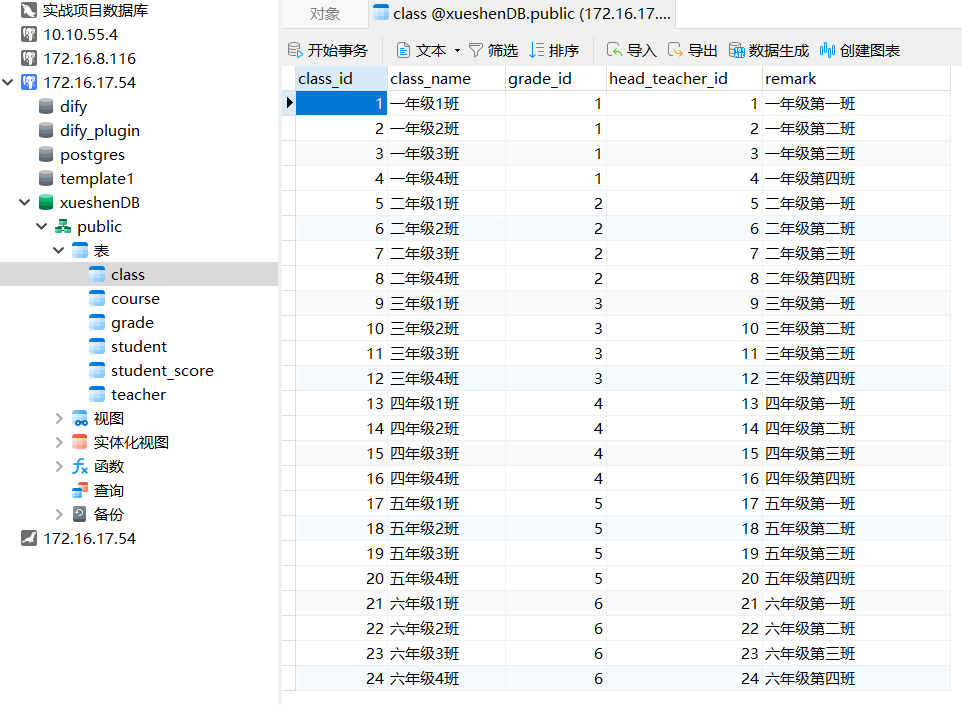
5.1准备数据库使用数据
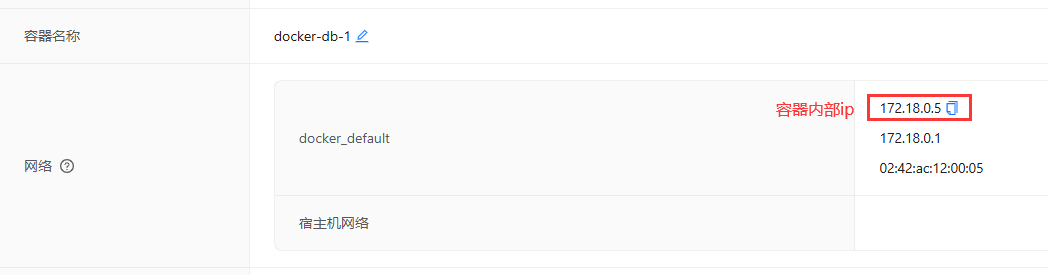
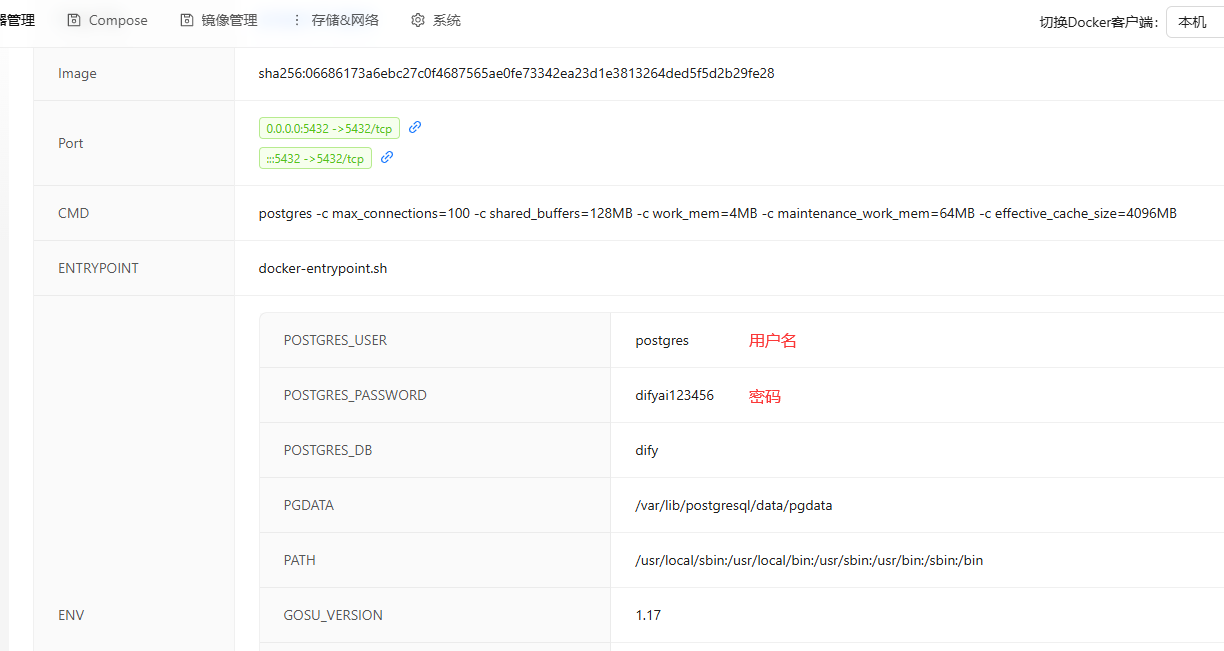
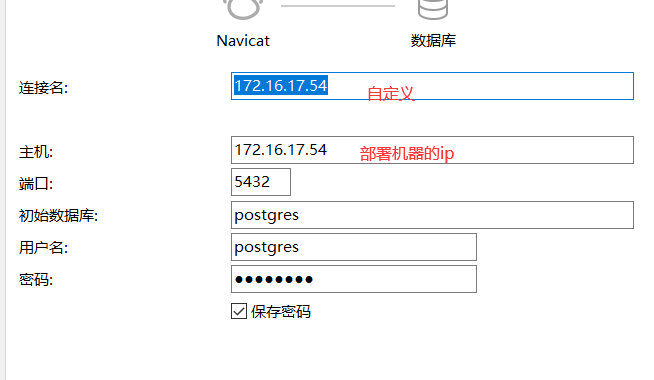
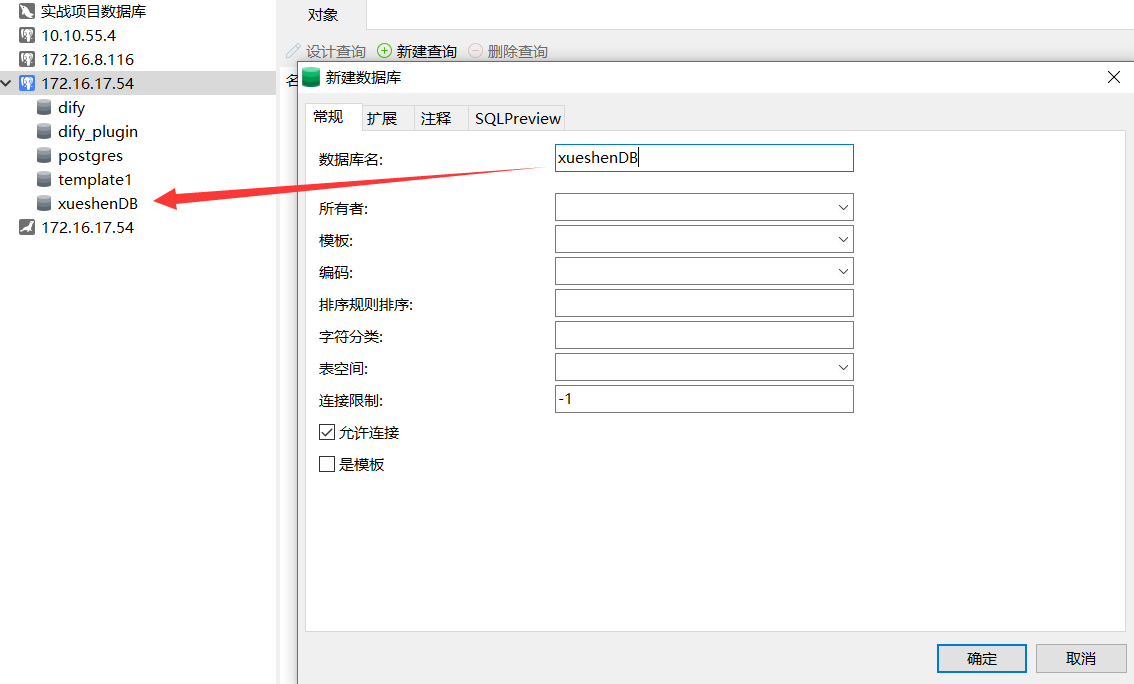
运行sql文件
# sql文件下载地址(需要有ipv6地址才能访问或用手机流量访问)
http://git.yexu.fun/yexu/script_backup/src/master/pgsql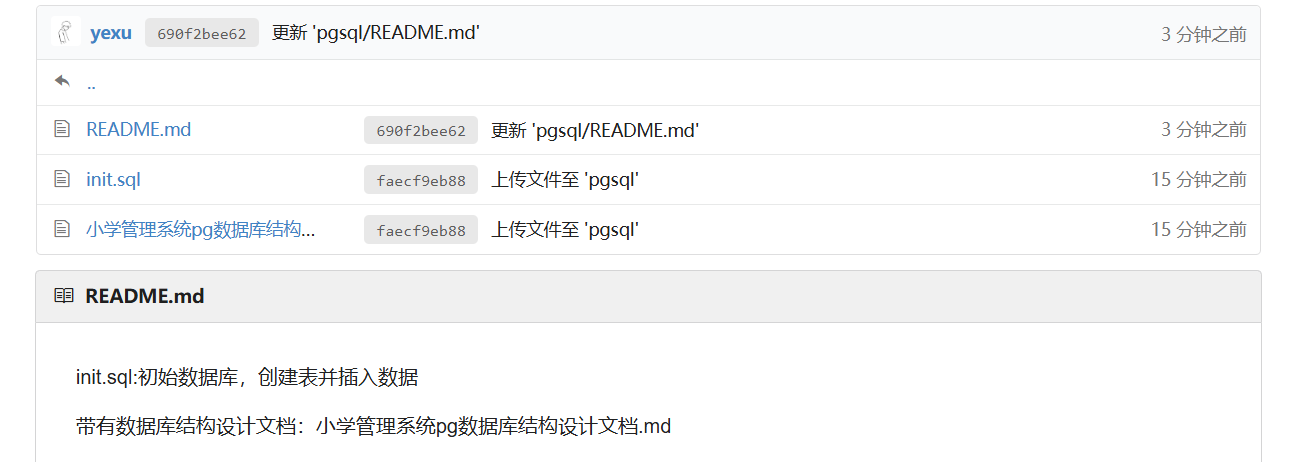
 5.2dify使用操作
5.2dify使用操作
推荐观看up主炼丹师马木木的视频:【【有手就会】10分钟带你用Dify搭建一个可视化数据分析助手,零代码实现数据库查询、图表展示、Excel生成,超简单!小白也能轻松学会 大模型|LLM-哔哩哔哩】
5.2.1配置应用大模型
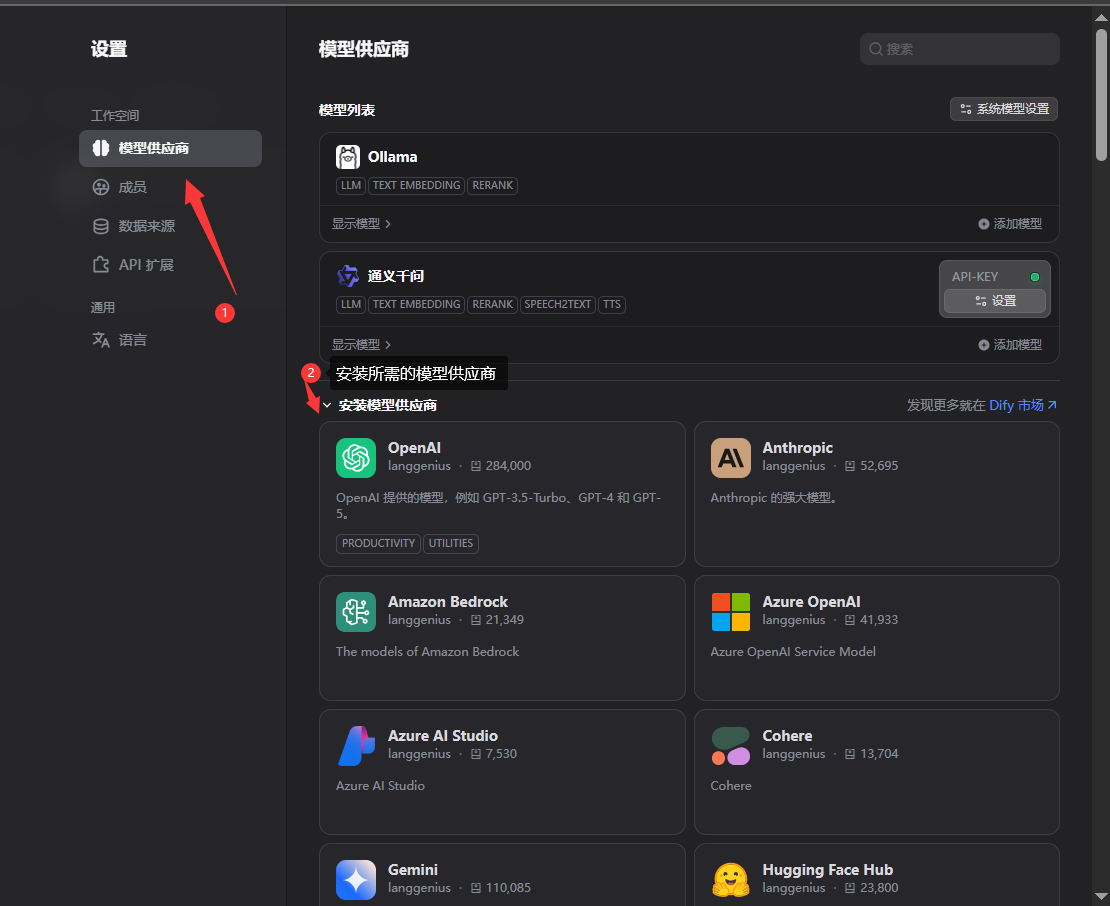
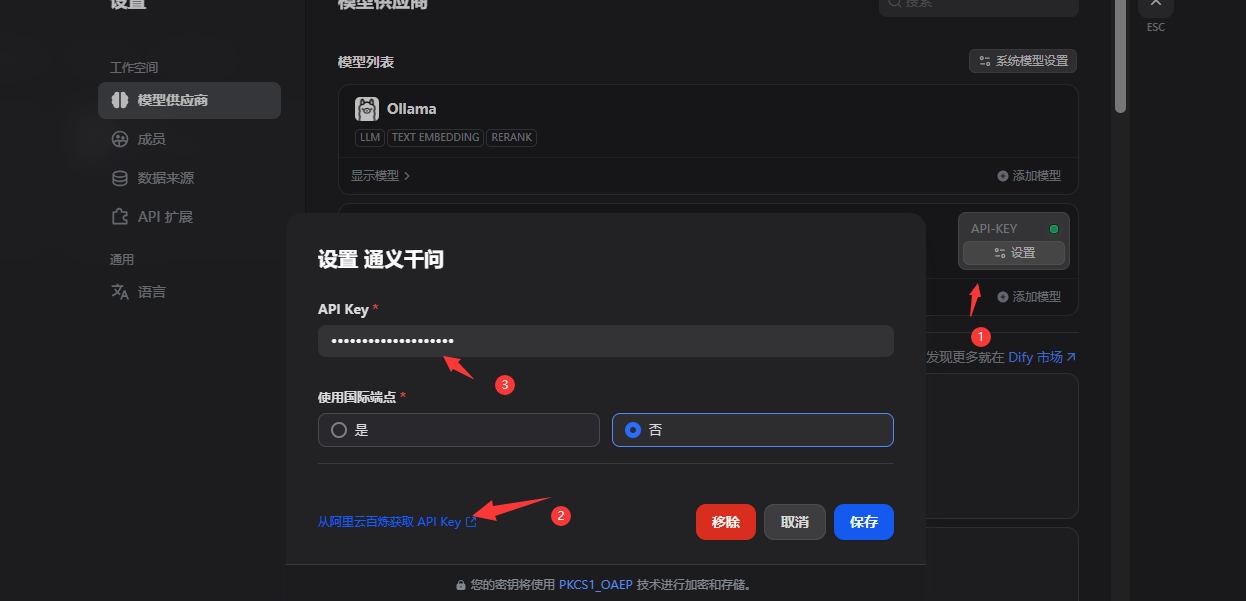
注:这里建议使用阿里云百炼,优点是不用自己搭建,大模型处理性能高。
5.2.2安装工具
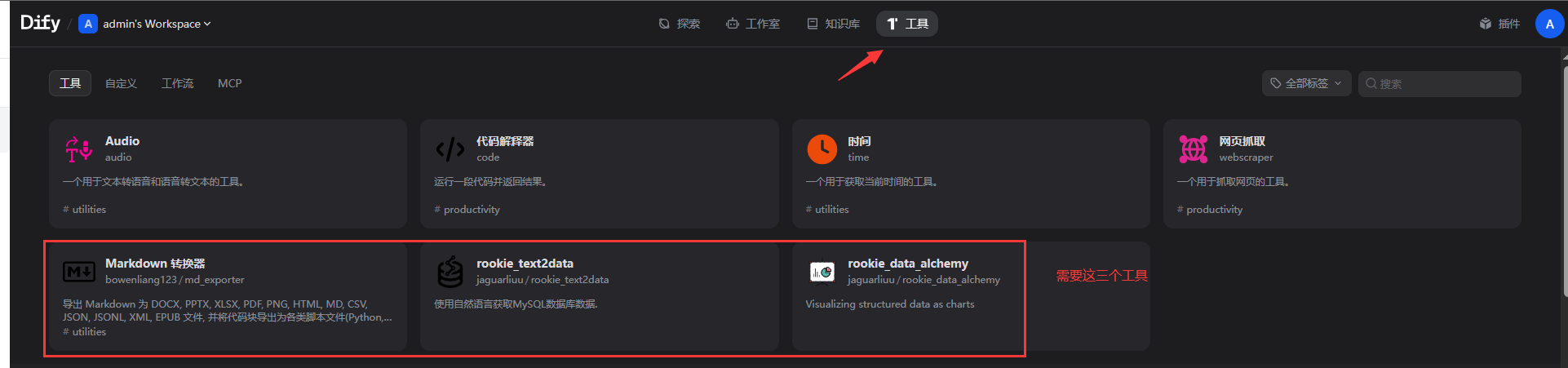
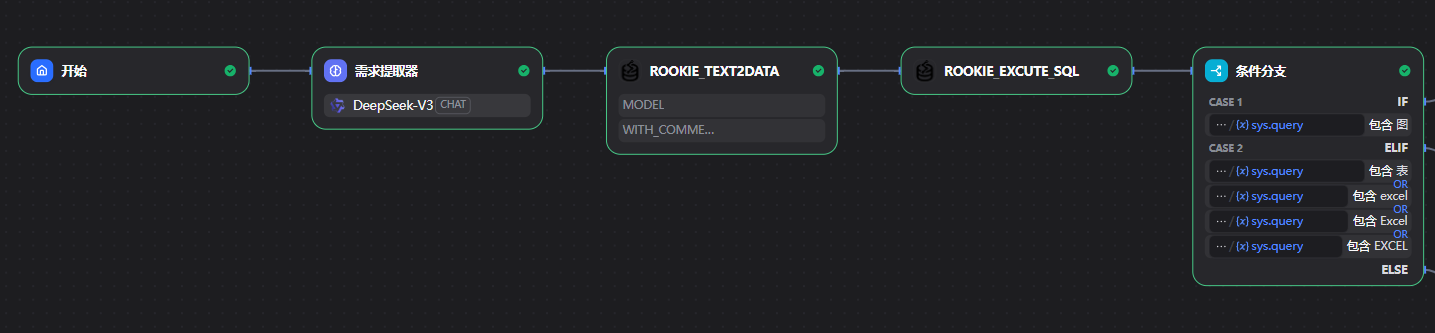
5.2.3创建对话工作流>填写应用名称>点击创建
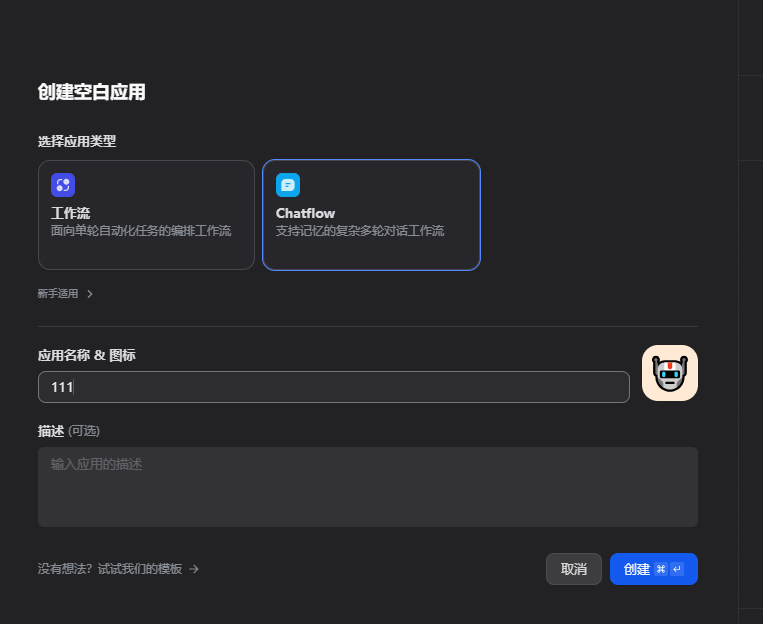
5.2.4点击添加LLM节点
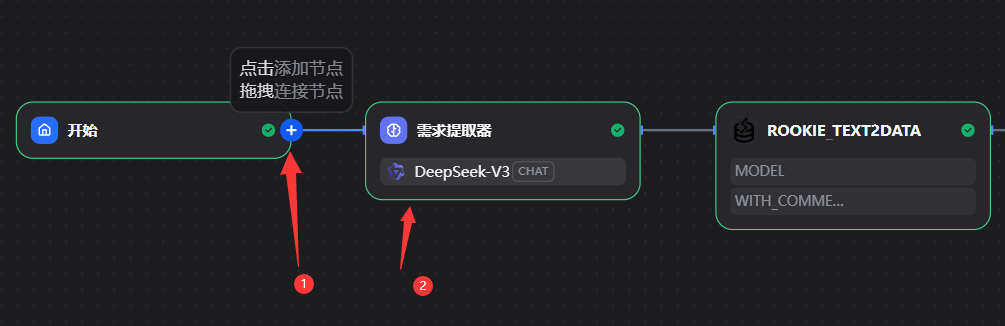
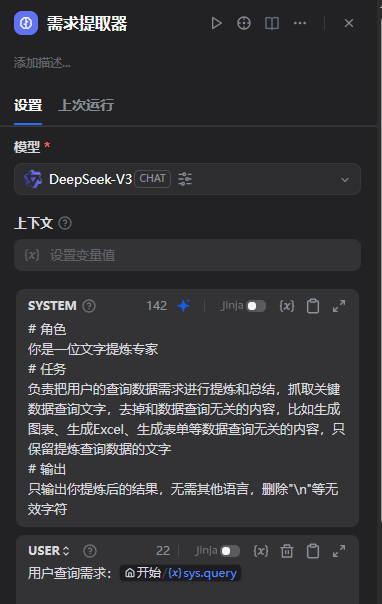
# 角色
你是一位文字提炼专家
# 任务
负责把用户的查询数据需求进行提炼和总结,抓取关键数据查询文字,去掉和数据查询无关的内容,比如生成图表、生成Excel、生成表单等数据查询无关的内容,只保留提炼查询数据的文字
# 输出
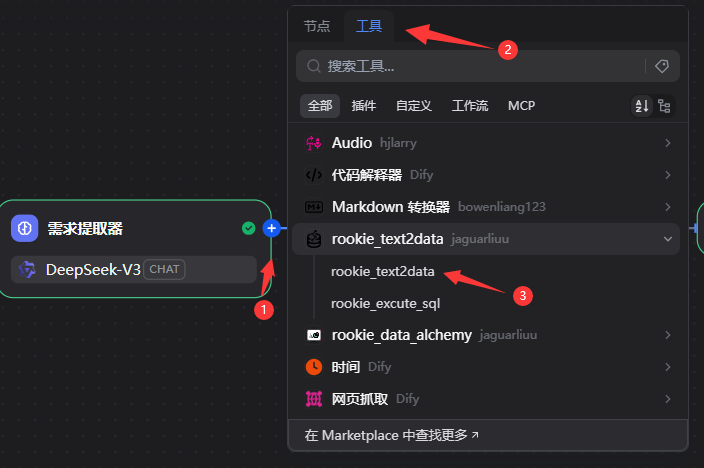
只输出你提炼后的结果,无需其他语言,删除"\n"等无效字符5.2.5添加rookie_text2data节点

# 这里使用的ip一定要用容器内部ip,否则会连不上数据库
# 数据库表名称
grade,class,course,teacher,student,student_score
# 自定义提示
表1 年级表(grade)
grade_id SERIAL (PK) 年级编号
grade_name VARCHAR(20) 年级名称
remark TEXT 备注信息
表2 班级表(class)
class_id SERIAL (PK) 班级编号
class_name VARCHAR(20) 班级名称
grade_id INT (FK) 所属年级
head_teacher_id INT (FK) 班主任编号
remark TEXT 备注信息
表3 老师表(teacher)
teacher_id SERIAL (PK) 老师编号
teacher_name VARCHAR(50) 老师姓名
course_id INT (FK) 所教课程
remark TEXT 备注信息
表4 课程表(course)
course_id SERIAL (PK) 课程编号
course_name VARCHAR(50) 课程名称
remark TEXT 备注信息
表5 学生表(student)
student_id SERIAL (PK) 学生编号
student_name VARCHAR(50) 学生姓名
age INT 学生年龄(6~12岁)
gender CHAR(1) 性别(男/女)
class_id INT (FK) 所属班级
remark TEXT 备注信息
表6 学生成绩表(student_score)
score_id SERIAL (PK) 成绩编号
student_id INT (FK) 学生编号
course_id INT (FK) 课程编号
score NUMERIC(5,2) 成绩(0~100)
remark TEXT 备注信息
5.2.6添加rookie_excute_sql工具
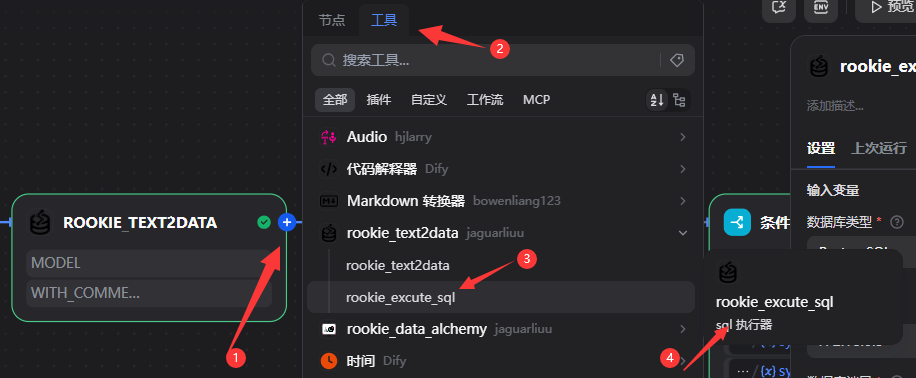
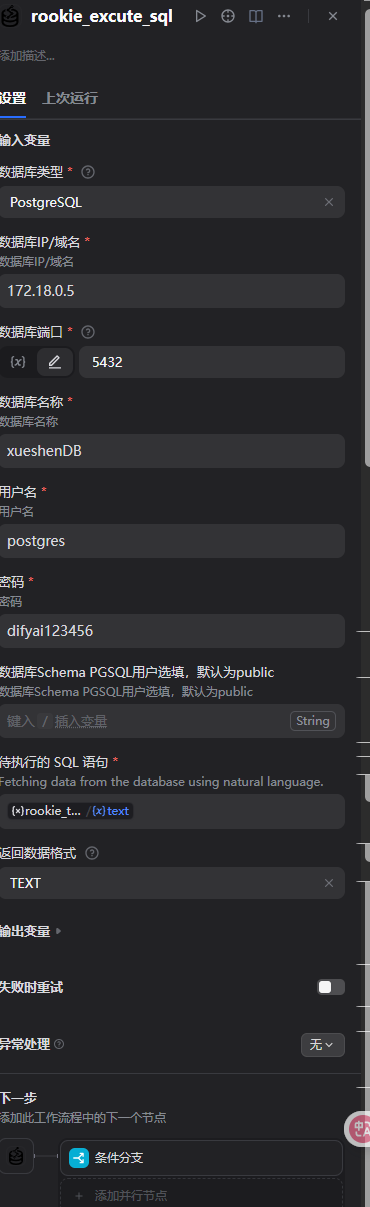
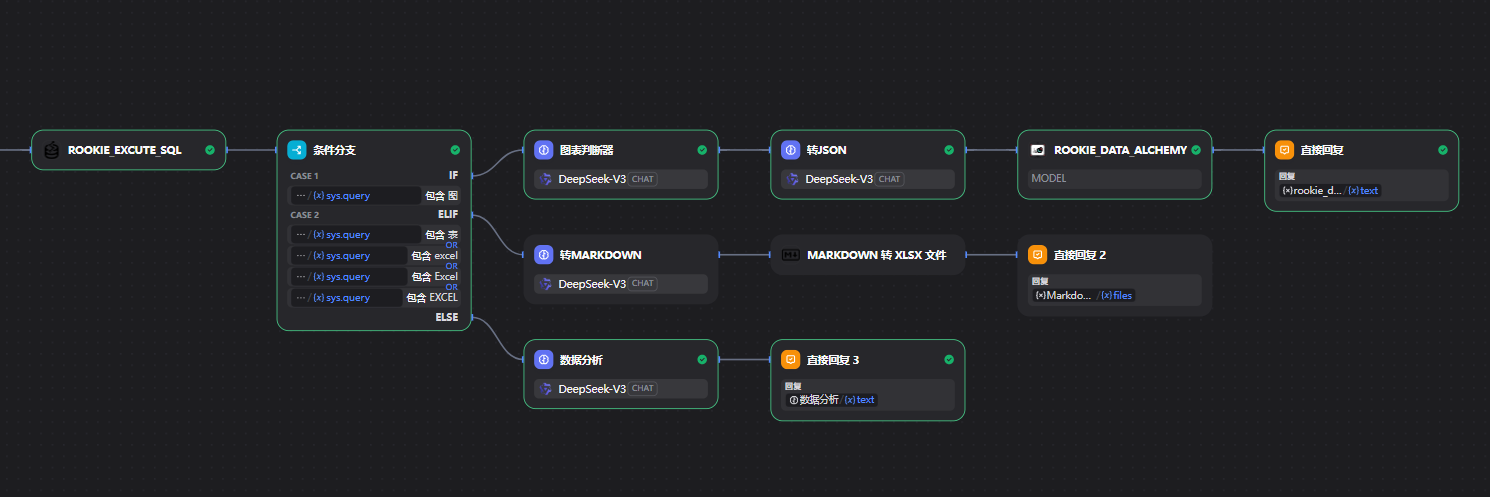
5.2.7添加条件分支
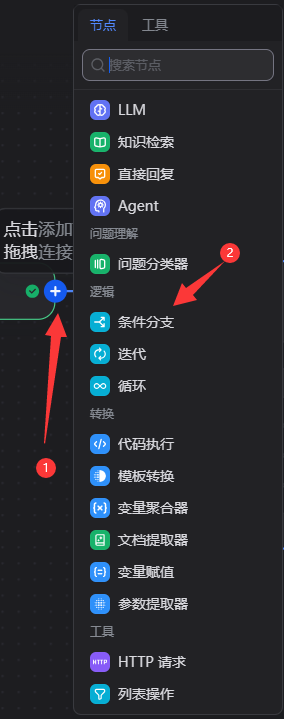
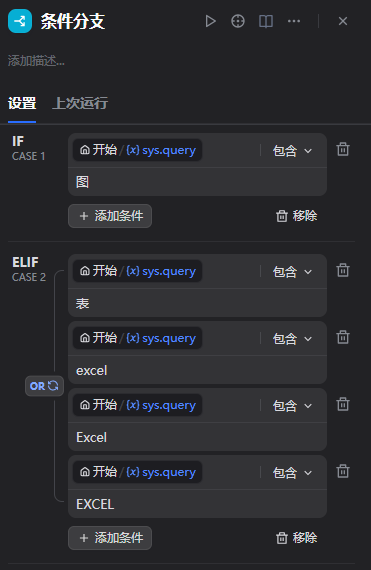
5.2.8图判断
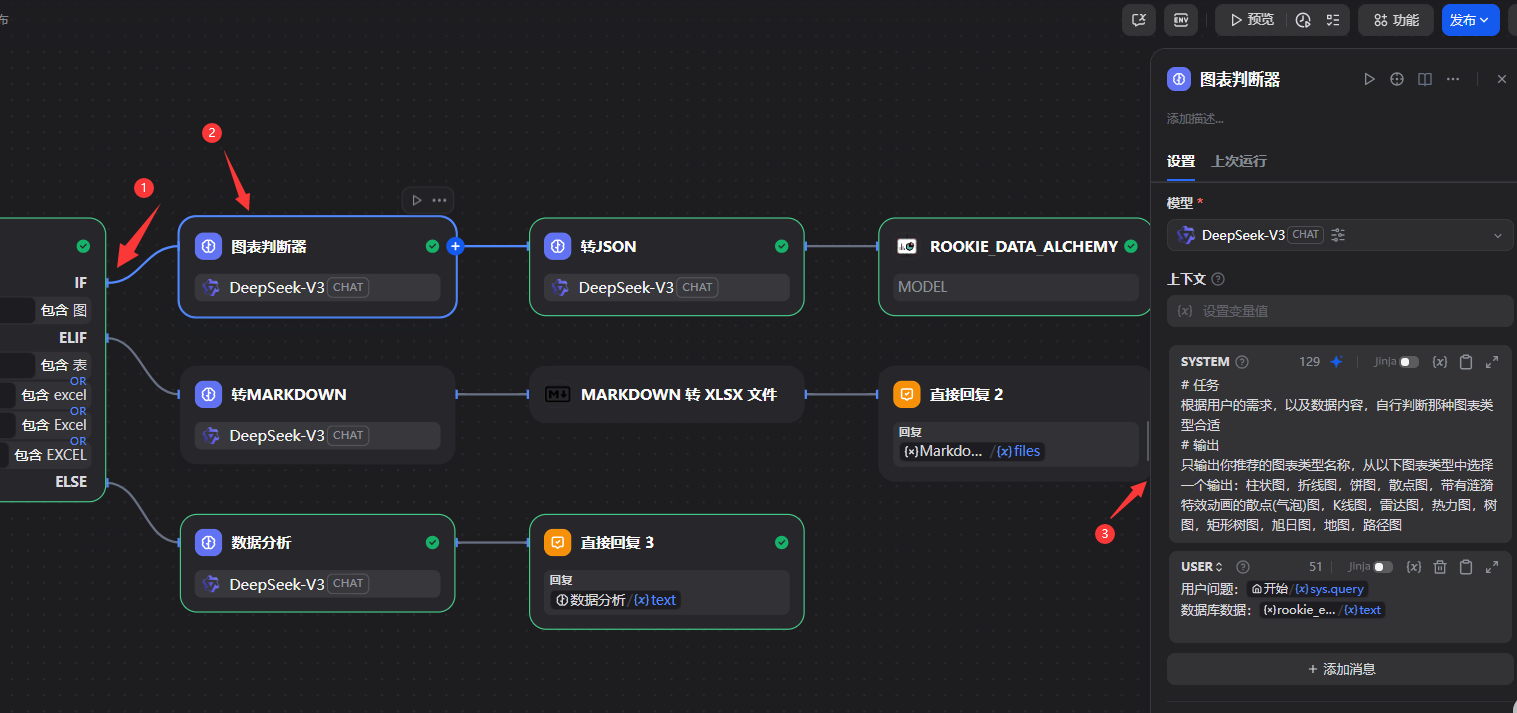
# 任务
根据用户的需求,以及数据内容,自行判断那种图表类型合适
# 输出
只输出你推荐的图表类型名称,从以下图表类型中选择一个输出:柱状图,折线图,饼图,散点图,带有涟漪特效动画的散点(气泡)图,K线图,雷达图,热力图,树图,矩形树图,旭日图,地图,路径图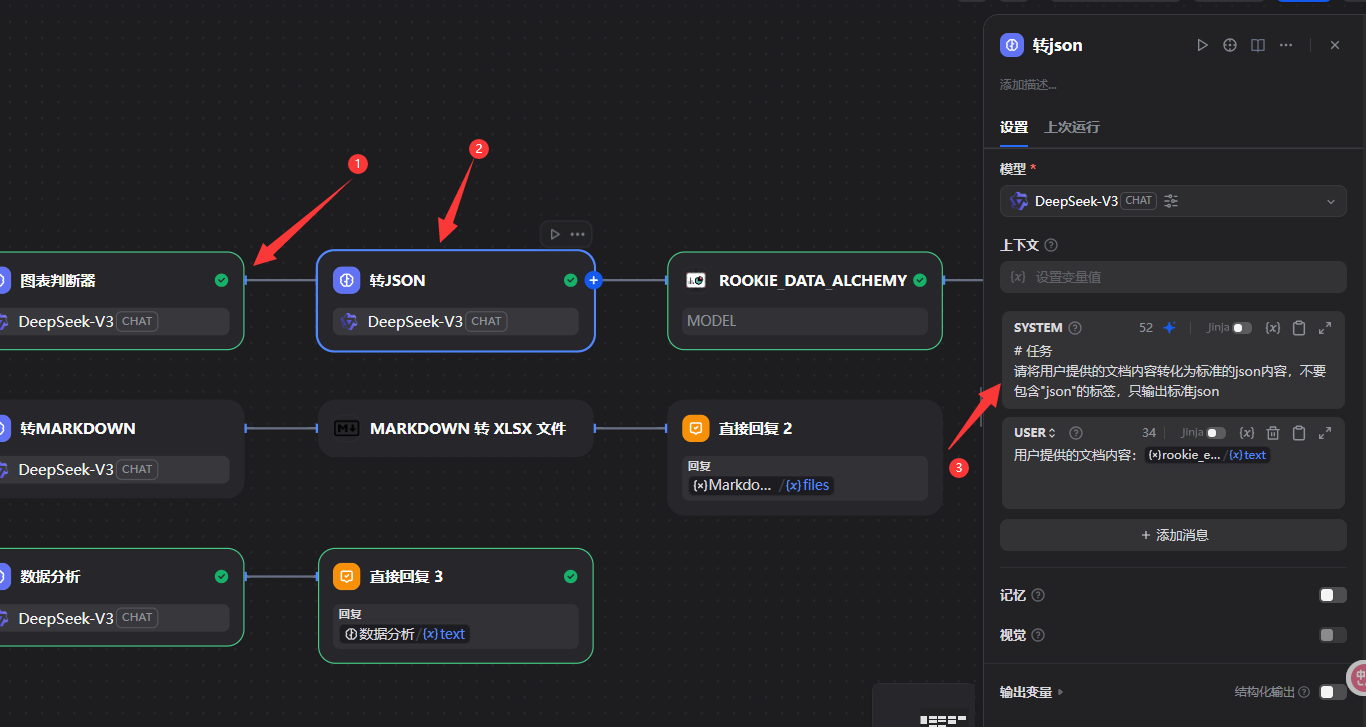
# 任务
请将用户提供的文档内容转化为标准的json内容,不要包含"json"的标签,只输出标准json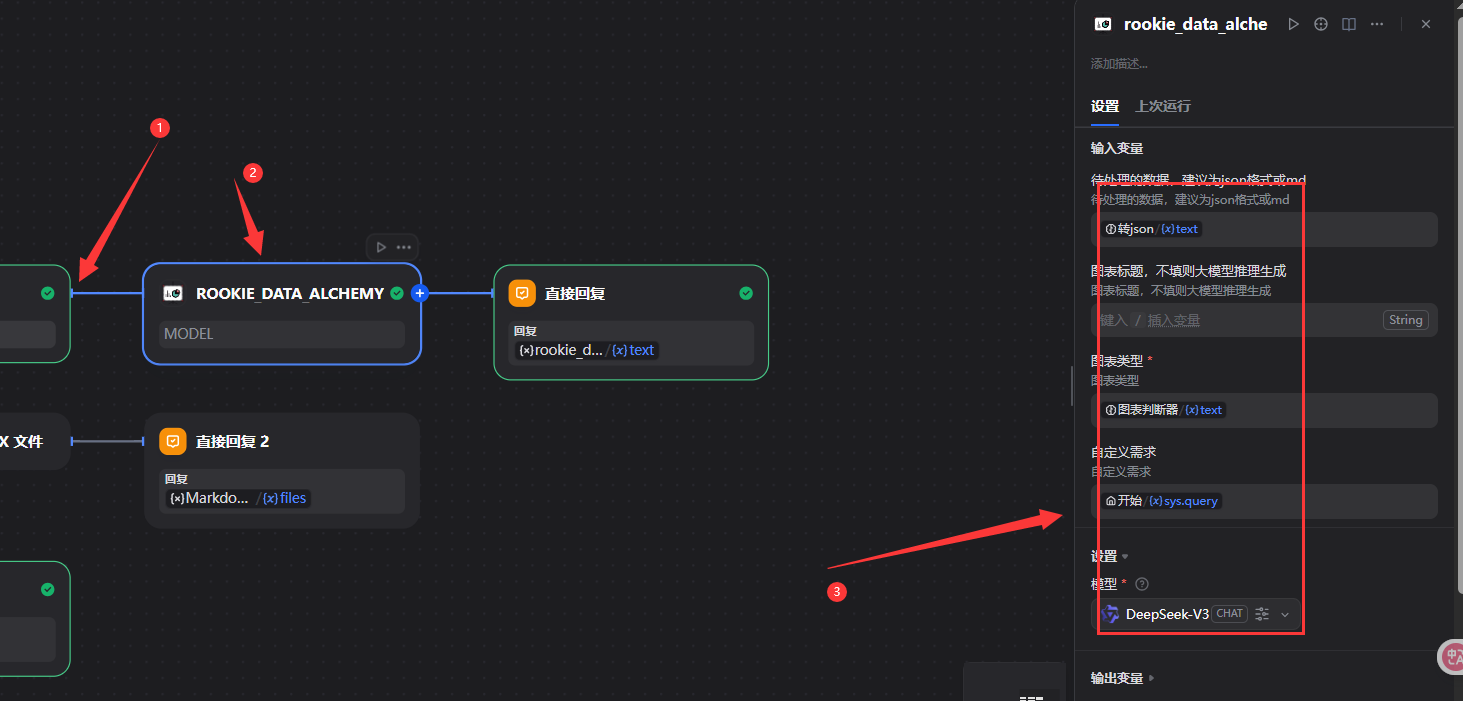
5.2.9判断excel文件
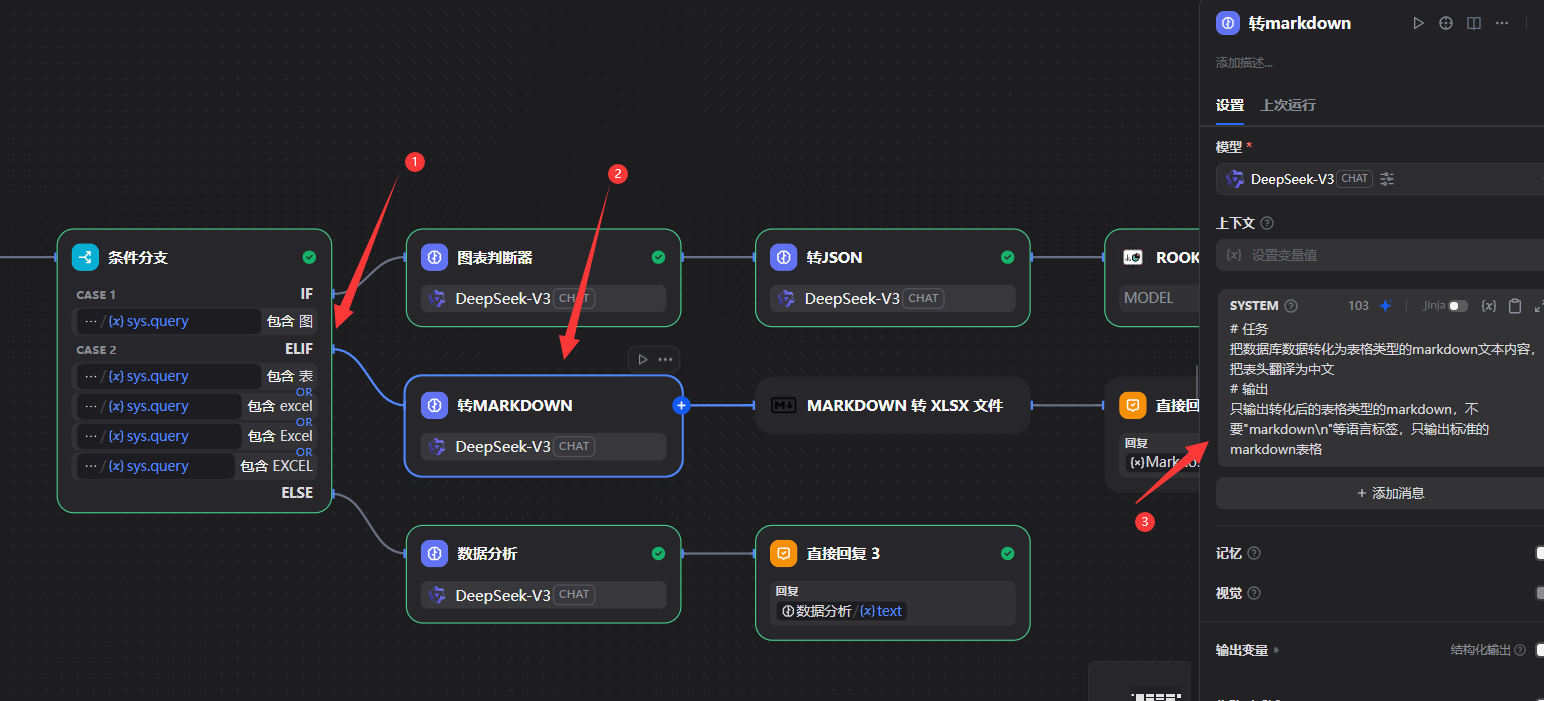
# 任务
把数据库数据转化为表格类型的markdown文本内容,把表头翻译为中文
# 输出
只输出转化后的表格类型的markdown,不要"markdown\n"等语言标签,只输出标准的markdown表格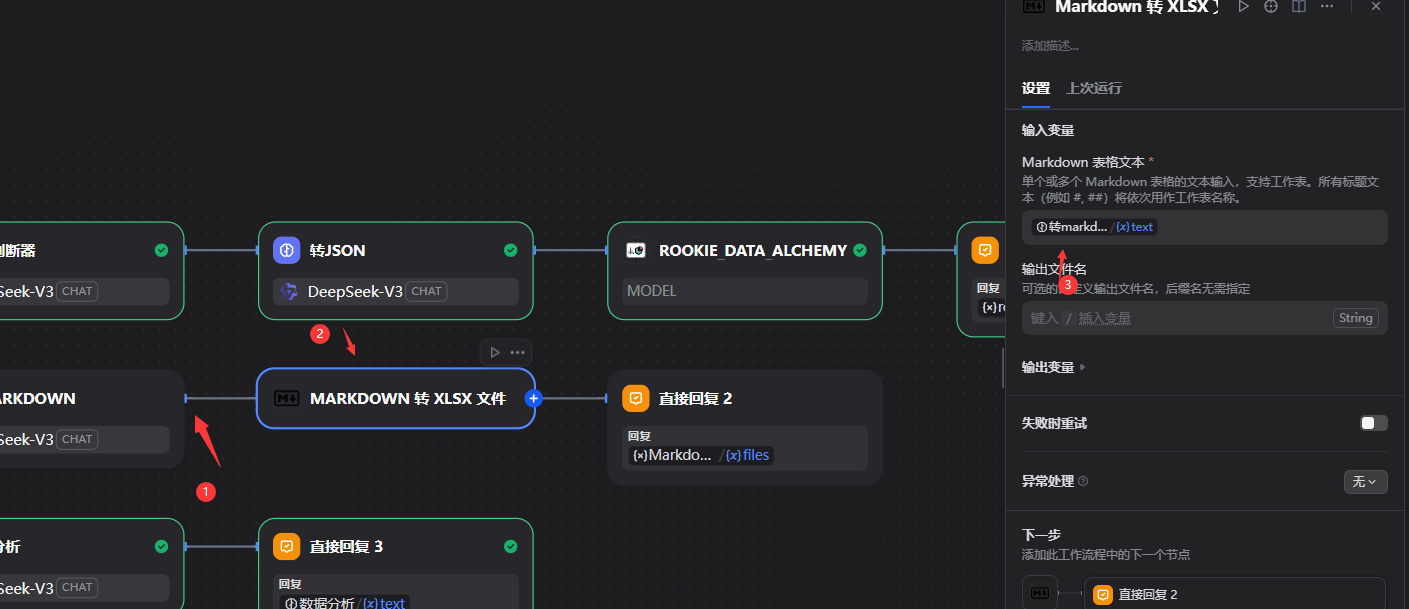
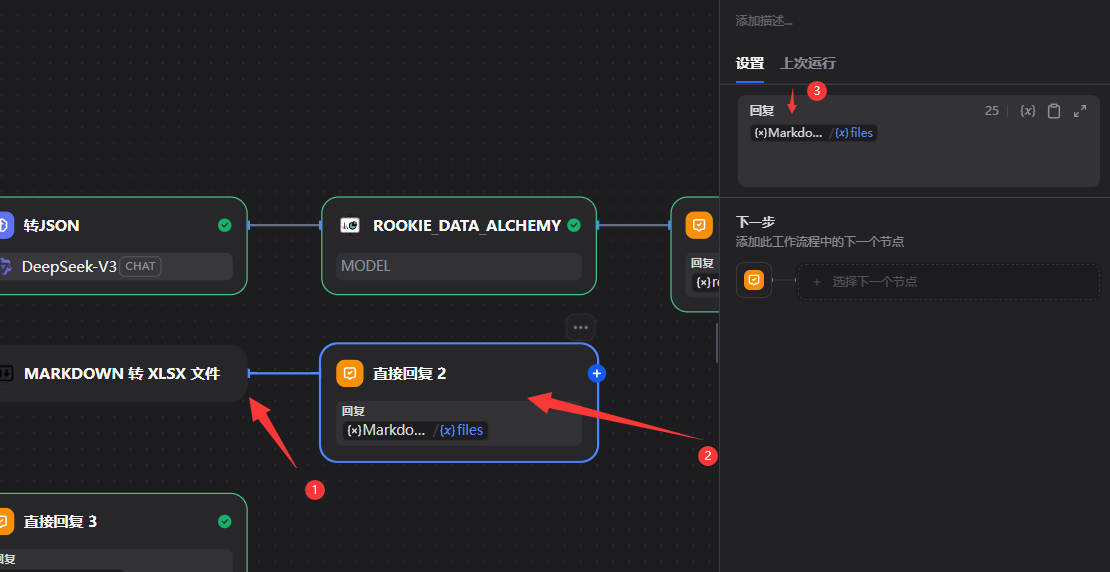
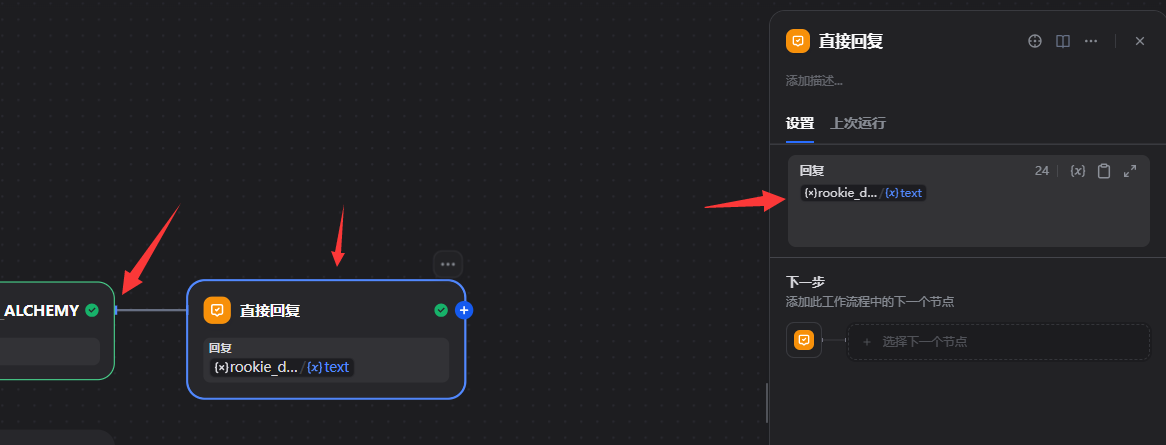
5.2.10直接回复
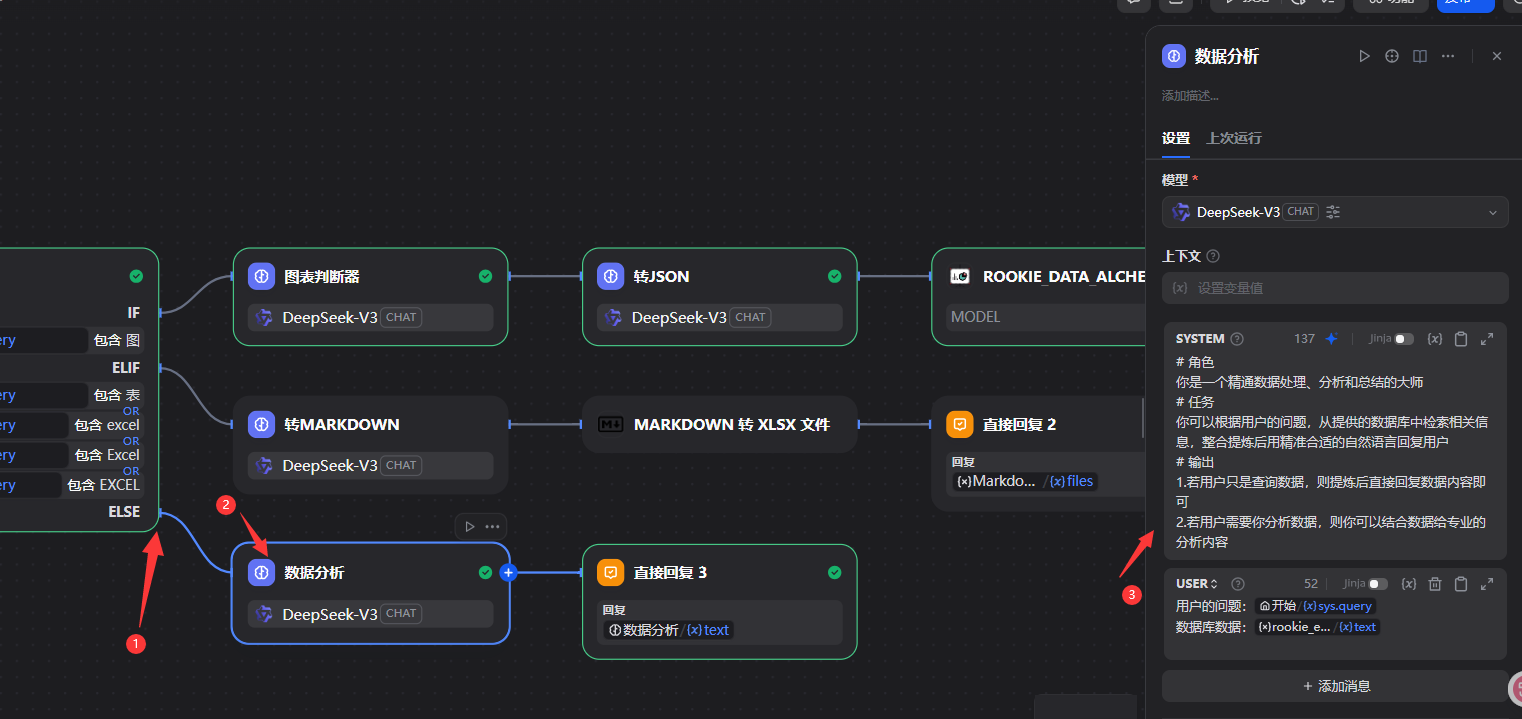
# 角色
你是一个精通数据处理、分析和总结的大师
# 任务
你可以根据用户的问题,从提供的数据库中检索相关信息,整合提炼后用精准合适的自然语言回复用户
# 输出
1.若用户只是查询数据,则提炼后直接回复数据内容即可
2.若用户需要你分析数据,则你可以结合数据给专业的分析内容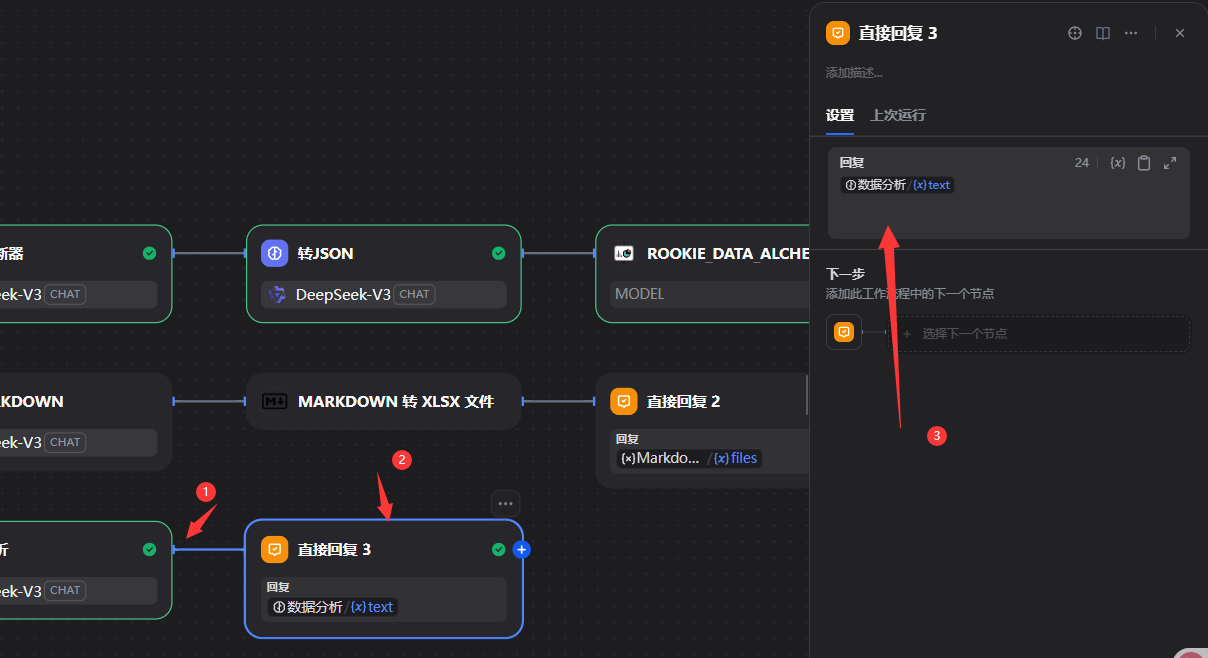
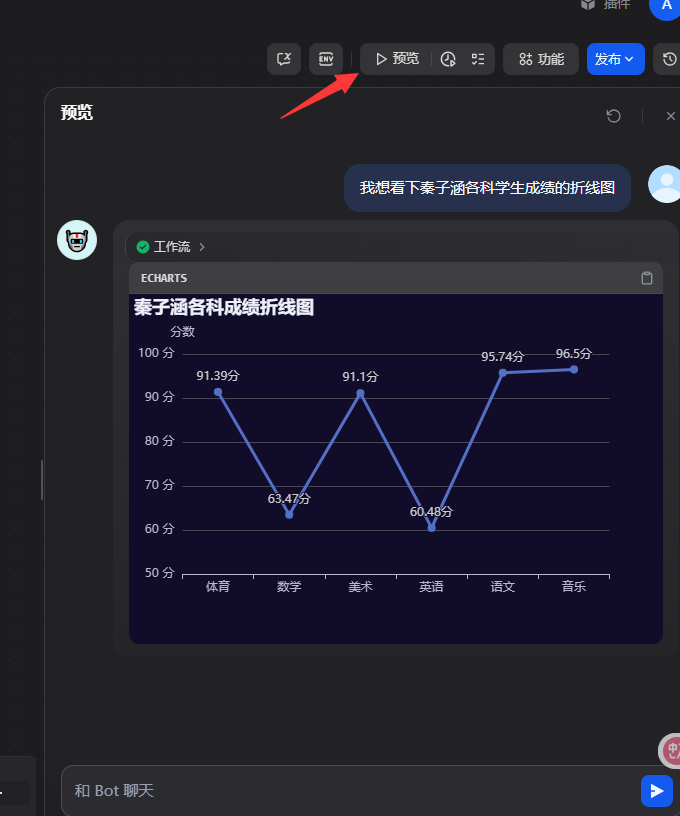
5.2.11整体及使用